Google Gemini生成的摘要
这一年我把 AI 写代码从松散的 vibe coding 调整成更可交付的 agentic engineering:人负责目标、边界、架构和最终 review,AI 负责上下文检索、补丁生成、命令执行和验证。文章记录了我在老系统、浏览器插件、Flutter/Cloudflare 跨栈项目里的真实工作流,以及工具编排、事实核查和提示词约束的阶段性经验。
最近这一年我用 AI 写代码的方式变了挺多。早期就是把它当输入法的延伸,让它补几行;现在大部分时间,它在帮我读代码、找链路、跑命令、出补丁、跑测试。但有一件事我一直没让 AI 接手:架构决定,还有最后那道 review。
下面写的是我在 AdExtend、几个浏览器插件项目,加上一些 Cloudflare/Flutter 应用里攒下来的经验。不是工具测评,更像写给自己看的一份阶段性记录。
1. Vibe coding 玩着爽,到不了交付
Karpathy 在 2025 年提出 vibe coding 之后,这个词很快就火了。做法挺简单:用自然语言把需求说出来,让 AI 出代码,看到报错就让 AI 改,到能跑为止。中间几乎不读代码。
写原型挺合适。一次性脚本、个人小项目、试探性 demo,几小时就能跑起来。以前因为不熟某个栈不太想动手的小点子,现在没什么门槛。
到了生产系统就不太一样。Addy Osmani 在《Agentic Engineering》那篇里讲得很直白:能交付的 AI 编码该有计划、有任务约束、有 review、有测试,架构和正确性最后落到人头上。Simon Willison 把这一类称作 vibe engineering 或 agentic engineering,跟松散的 vibe coding 区分开。要进生产环境,版本控制、测试、review、可观测性这几样工程素质少不了。
AI 写得再快,业务出问题还是我的事。
2. 几个真实场景
改老系统:先把链路看透
AdExtend 这种已经跑了一段时间的业务系统里,让 AI 凭空写功能很容易翻车。它真正能帮上忙的是把复杂链路打通。
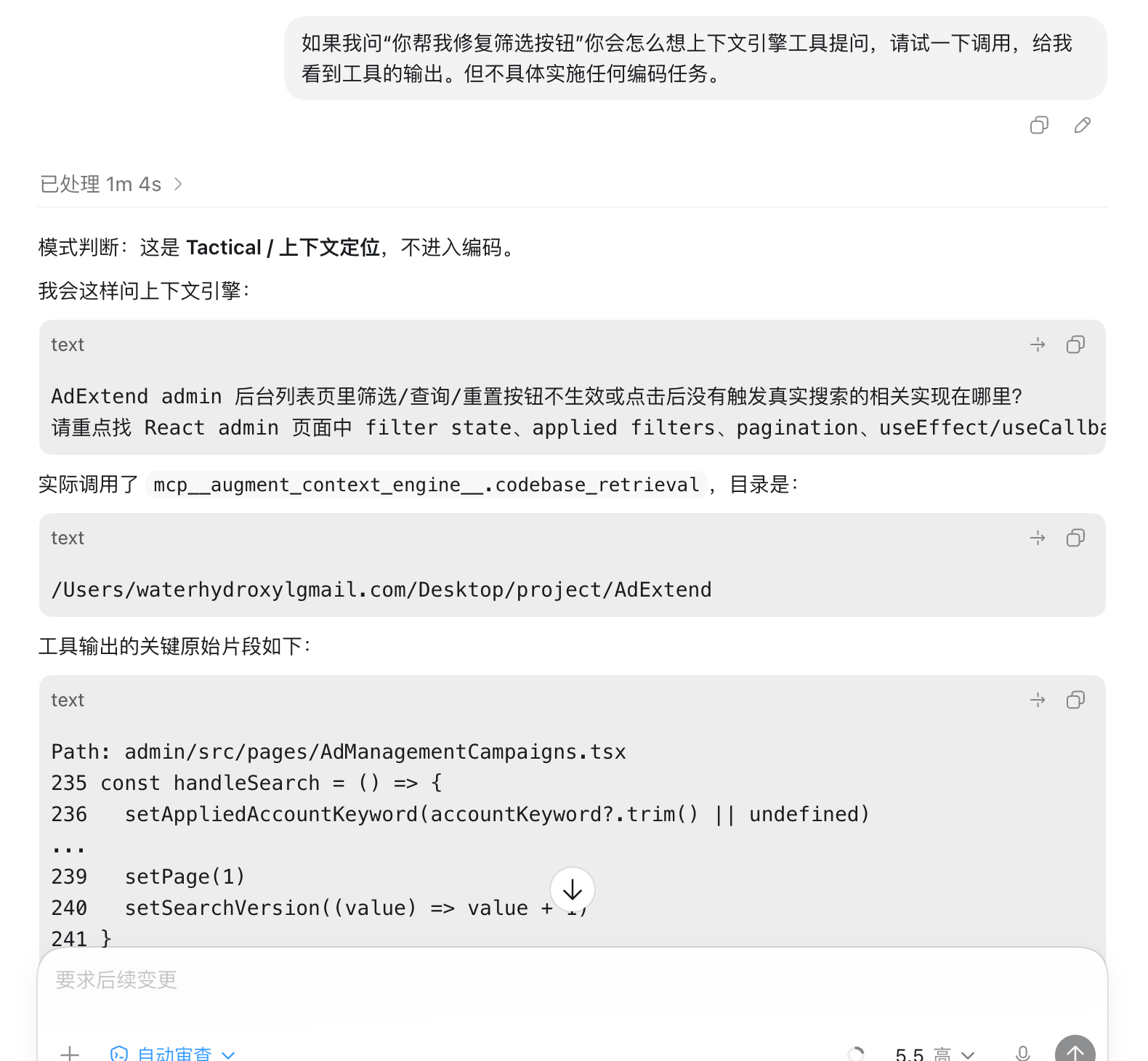
举个例子:后台筛选按钮点了没反应。表面上是按钮坏了,往下挖原因可能多层。前端 effect 漏了依赖。服务端 route 没把参数透传下去。SQL mapper 里少拼了条件。页面 reset 之后没触发真实搜索。也可能本地分支跟线上版本根本不是一回事。落点经常出乎意料。
如果直接丢一句”修一下筛选按钮”给 AI,大概率拿回一个局部对、整体错的补丁。我现在做法笨一点:先让它用语义检索或 rg 找入口,让它读真实文件,再顺着请求参数、route、SQL、返回字段一路追下去。找到最小修改点再动手,改完跑测试,跑不动就跑一次接口或页面验证。验不了就明确说验不了。
关键还是给它真实上下文。喂得越真,它编得越少。

插件和浏览器自动化:代码看着支持,未必真能跑
浏览器插件、Facebook Ads Manager、TikTok Ads 这类场景,光看静态代码只能回答一半问题。
“任务为什么一直 pending”这种问题,不能只看服务端有没有把任务塞进队列。background 拉到没拉到,content script 注没注入,当前页面是不是匹配的平台和账号,登录态够不够调那个接口,请求 shape 跟页面真实发出去的对不对得上。这几层任意一处断开,外面看到的现象都是”卡住”。
所以我经常用 BrowserMCP、Chrome DevTools 加 opencli。不上真实浏览器,AI 容易把”代码里看着支持”当成”页面里真的能跑”。
我踩过的一个典型坑:静态枚举里有某个操作类型,并不代表运行链路真的实现了那个能力。dispatcher、权限、页面上下文、实际网络请求都得看一遍,必要时还得在已登录页面里做一次最小探测。
Flutter / Cloudflare / Worker:跨栈最怕”顺手做大”
Flutter + Cloudflare Worker + R2/D1 这种跨栈项目里,AI 特别容易顺手做大。前端、后端、部署脚本、README、权限模型一次性全改。看着完整,风险也最大。
我现在会先把边界切清楚。Flutter 端只管 UI 和上传流程,Worker 端负责鉴权和预签名 URL,Cloudflare 配置归 wrangler 那一摊。如果用户说了”先只动前端”,那就别顺手补 Worker。AI 编码最难的环节其实是怎么控住范围。

3. 工具编排比模型选型重要
刚开始用 AI 写代码那阵,我盯模型本身:谁更会写代码、谁上下文长、谁补全更聪明。现在更在意工具链怎么搭。
我目前的常用组合大概是这样。augment-context-engine 和 rg 找跨文件链路。context7 查第三方库 API,避免凭记忆写过期方法。exa 查时效性资料和外部讨论。BrowserMCP、Chrome DevTools、Playwright 用来打开真实页面,看 DOM、控制台和网络请求。opencli 处理小红书这类社交平台的检索。Flutter skill 处理布局和测试。Wrangler 处理 Worker、D1、R2、部署。最后回到 Codex 落代码、审 diff、跑验证。
背后只有一条原则:不同类型的事实,交给不同工具去查。代码事实归仓库,运行事实归本机和浏览器,API 事实归官方文档,时效信息归搜索,业务判断由人确认。AI 在这里负责的事情其实很窄,就是把这些证据组织得更快一点。
模型分工,别让一个模型干所有事
我不太信”一个模型包打天下”。更靠谱的方式是把模型当成不同能力的执行角色用。有的适合开放式讨论,有的适合长时间贴着代码跑,有的负责便宜快速地处理重复劳动。
这个判断不全是个人体感。对照公开文档之后,我会把结论说得保守一点。
Google 给 Gemini 的定位是复杂任务、深度推理、编码和多模态理解。Vertex AI 文档里写得清楚:text、code、image、audio、video,乃至整个代码仓库这种信息源它都能处理。
Claude Code 官方文档强调的是 agentic coding:读代码、改文件、跑命令、搜索、调试,靠工具循环把任务推下去。它的模型档位也写得直接:Sonnet 处理日常编码,Opus 留给复杂推理和架构决策。(如果只使用 Claude Code 一款工具,为了成本效益可以使用 /model opusplan)
Codex 偏的是”在当前仓库里做可验证的执行”。围绕文件读取、补丁修改、命令运行、测试验证、subagent 分工和代码审查形成闭环。
我现在大致这么用。方案设计、原型讨论、把外部资料和截图归纳到一起的活儿丢给 Gemini。复杂代码改动、跨文件的任务编排、长链路的执行流程交给 Claude Code。最后落代码、审 diff、跑可复现验证回到 Codex。批量整理、格式转换这种低风险重复劳动,便宜的快速模型就够。
我会把分工直接写进任务提示词:
按任务性质选模型和工具:方案设计、原型、外部资料归纳优先用 Gemini;复杂代码、任务拆解和执行编排参考 Claude Code 工作流;最终代码改动、diff 审查、测试验证回到当前 Codex 工作区完成。任何模型输出都是候选方案,不能替代仓库证据和可复现验证。
要紧的是别把”开放式讨论”和”生产级修改”塞进一个上下文里。讨论阶段可以多模型一起想,执行阶段必须回到当前仓库、测试、日志、浏览器和真实 API。
单独搞一层”反幻觉事实核查”
AI 编码里最危险的幻觉是看着挺像真的那种。语气夸张的反而不太骗人。
它会编出一个根本不存在的 SDK 方法。会用上已经废弃的 CLI 参数。会把旧版本框架的行为说成当前行为。会把博客里某个人的经验当成官方约束。本地代码里”看着支持”的枚举,被它当成线上真的能用。一次浏览器渲染成功,被它当作业务链路全跑通。
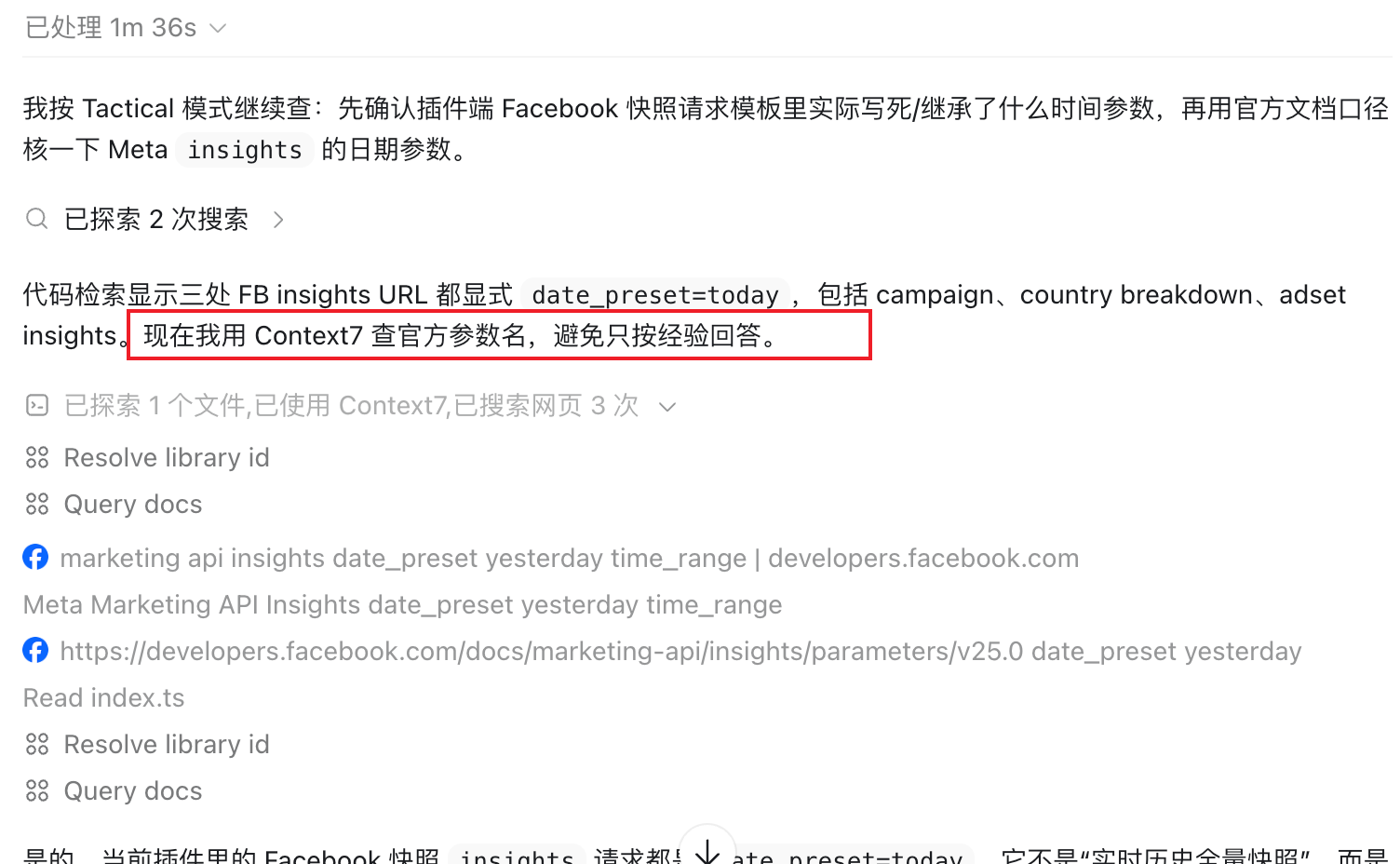
所以我现在按事实类型给来源排了个序。代码事实只看当前仓库和当前分支。运行事实看本机命令、浏览器页面、网络请求和数据库查询。API 事实优先官方文档,博客和问答靠后。时效信息必须重新搜,不靠模型记忆。业务事实以当前产品约束和用户确认为准。
exa 和 context7 在这里负责两类不同的核查。
exa 适合查”外部世界现在怎么说”。写这篇文章前,我用它在 X、博客、技术社区里翻了一圈 vibe coding、agentic engineering、AI coding workflow 的讨论,确认这个行业叙事是不是真的在从”AI 帮我写代码”转向”人负责架构、审查、验证,AI 负责执行”。这种问题有时效性,模型记忆未必跟得上。
context7 解决的是”这个库现在该怎么用”。React、Next.js、Cloudflare Workers、Prisma、Tailwind、Flutter 生态里的 API 和配置经常随版本变。这种活儿我不希望 AI 凭记忆写代码。先 resolve library id,查当前文档,确认方法签名、配置位置、废弃项和推荐写法。
两者边界要清楚。exa 解决外部事实和时效,context7 解决库和 SDK 的官方用法。一个任务两边都涉及的时候(比如调研 Cloudflare Workers 上某个新能力是不是适合当前项目,再做最小 PoC),我会先用 exa 看外部限制和案例,再用 context7 查官方 API,最后回到仓库做最小实现和本地验证。
提示词里我直接写清楚:
涉及第三方库、SDK、云服务或 CLI 参数的,先用 context7 或官方文档确认当前版本用法;涉及近期行业观点、产品变化、平台规则或外部案例的,先用 exa 检索并交叉验证。不要靠模型记忆直接编码。最终结论必须回到当前仓库、运行结果和可复现验证。
看着啰嗦,但能少踩很多”代码生成出来了,事实却是错的”那种坑。真正麻烦的情况不是 AI 写不出来,是它写得很顺、错得很隐蔽。

4. 提示词怎么写
那种”你是世界顶级工程师,请帮我实现一个高质量系统”的提示词我现在写得越来越少。看着震撼,落到工程上没什么用。
更管用的是约束。当前目标是什么。哪些文件可能相关。哪些行为不能动。先读哪些上下文。第三方 API 必须查文档。修改范围最小化。验证命令是哪个。如果发现范围外的问题,提示一下就好,不要自己动手。
举个我会写出来的提示:
不影响 Node 服务其它行为的前提下,只修复 admin 列表页查询/重置不触发真实请求的问题。先看同类页面有没有共享缺陷,再做最小改动。改之前读真实文件,改完跑现有前端检查。测试跑不了,把原因说清楚。
没什么花词,但把 AI 圈进了工程边界。
5. 审查的活反而变多了
Karpathy 在 2026 年初的一次分享里说,他的工作流已经从”主要手写代码”切到”主要让 agents 写代码,自己做编辑和修补”。但他也提醒一句:AI 出错的方式像一个匆忙的初级工程师。会乱做假设,不会主动澄清矛盾,会过度抽象,会用一千行解决一百行的问题。
我自己经验也是这样。AI 越能一次改 20 个文件,瓶颈就越往审查环节挪。看不看得懂它改了什么;它有没有顺手扩大范围;有没有藏在某行里的行为回归;测试覆盖够不够;该不该让它退回到最小方案。
所以我不觉得 AI 编码降低了门槛。它把”打字”和”查样板”的成本压下去了,但系统理解、代码审查、测试设计、风险判断这几样反而吃功夫。
6. 我的阶段性判断
做 demo,vibe coding 已经够用。要交付生产系统,agentic engineering 这个名字更准确。
我理解的 agentic engineering 跟”人不写代码”不是一回事,差别主要在分工。人定义目标和边界,AI 检索上下文、生成实现、跑验证,人审查架构、风险、业务语义和最终的正确性。工具链负责把代码、浏览器、文档、日志、测试串起来。
工程师的价值未来可能不太体现在”亲手写了多少行代码”。能不能把问题定义清楚,能不能给 AI 正确的上下文,能不能设计可验证的交付路径,能不能识别模型输出里的错误假设,能不能对最终系统负责,这些才是位置变化之后的本职工作。
我目前的体会大概就是这条。AI 跑得快,但需要清晰的约束。工程基本功扎实的人,从这里能拿走的回报最高。
参考资料
- Addy Osmani, Agentic Engineering
- Simon Willison, Vibe engineering
- Codegen, What Is Vibe Coding and How to Actually Do It at Scale
- GLN-7.5, Karpathy: From Vibe Coding to Agentic Engineering
- Shiplight AI, Agent-First Testing: Build Quality Into Every AI Coding Session
- dev.by, AI writes 80% of my code
- Google AI for Developers, Gemini API models
- Google Cloud, Gemini 2.5 Pro on Vertex AI
- Anthropic, How Claude Code works
- Anthropic, Claude Code model configuration
- OpenAI Developers, Codex prompting
- OpenAI Developers, Codex subagents

AquaHydro
望穿他盈盈秋水,蹙损他淡淡春山。
7
1
14